Les expressions régulières débarquent dans la V12.3 !
- 7 mai 2025
- Envoyé par : LaetitiaB
- Catégorie: Technologie

Bonne nouvelle pour les utilisateurs de NatStar et NS-DK : les expressions régulières (ou regex) sont désormais intégrées à partir de la version 12.3 de nos applications métiers !
Cette évolution vous permet d’automatiser la recherche, la validation et la transformation de vos données de façon puissante et flexible.
Dans cet article, découvrez comment fonctionne une regex, ses principales constructions et quelques cas d’usage concrets pour optimiser vos traitements quotidiens.
1. Définition d’une expression régulière
Une expression régulière (regex), est une chaine de caractères spéciale utilisée pour décrire un motif (pattern) dans du texte.
Elle permet de :
- faire des recherches de sous-chaines dans un texte
- vérifier la validité d’une information
- remplacer une sous-chaine par une autre dans un texte.
Exemples :
– Recherche de sous-textes :
- extraire tous les numéros de téléphone, les mails, … d’un texte
–Vérification de la validité :
- vérifier qu’une chaine est un numéro de sécurité sociale valide
- vérifier qu’une chaine est un code postal français valide
-Remplacement de caractères :
- remplacer un caractère séparateur d’un texte par un autre
- remplacer les 0 / 1 représentant des booléens par false / true
- anonymiser les numéros de carte bancaire : remplacement par XXXX-XXXX-XXXX-XXXX
Les regex sont intégrées dans la plupart des langages de programmation (Python, Java, JavaScript, NCL) ainsi que dans de nombreux outils (grep, éditeurs de texte, bases de données, etc.).
2. Composition d’une regex
Une expression régulière est composée de symboles, de classes de caractères et de quantificateurs.
Exemples de symboles : ^, $, [, ], (, ), |, {, }
1.Classe de caractères
Une classe de caractères représente un ensemble de caractères acceptés à une position donnée dans le texte. Elle est notée par des crochets [] .
Elle peut désigner un sous-ensemble de lettres. Par exemple [abc] est une classe acceptant un seul caractère qui peut être ou a ou b ou c, en minuscule.
Ainsi la chaine “arbre” répond deux fois à cette condition tandis que la chaine “eau” y répond une fois et la chaine “solution” n’y répond pas.
Pour préciser une plage de lettres, placer un tiret entre le début et la fin de la plage. Ainsi [a-e] est une plage désignant toute lettre située alphabétiquement entre a et e, bornes incluses, soit a, b, c, d, e.
Pour préciser plusieurs plages, les juxtaposer sans espaces. Par exemple [a-cB-D] désigne toute lettre située alphabétiquement entre a et c en minuscule ou entre B et D en majuscule, soit a, b, c, B, C, D
Une plage peut être constituée de chiffres :
[0-9] : représente un chiffre décimal
[0-1] : représente un chiffre binaire (un 0 ou un 1)
Pour accepter le tiret, le placer à la fin du contenu des crochets afin de ne pas le confondre avec un tiret qui définit une plage. Par exemple la plage [a-c-] accepte un seul caractère qui peut être ou a ou b ou c, en minuscule, ou un tiret
Pour accepter le caractère espace, on peut le placer n’importe où.
On peut ainsi définir la classe des chiffres hexadécimaux avec espaces autorisés : [0-9A-Fa-f ]
Les caractères placés entre crochets n’ont pas besoin de figurer plusieurs fois.
En guise d’illustration [aaab] équivaut à [ab], [0-9 a-f A-F] (2 espaces spécifiés) équivaut à [0-9a-fA-F ] (un seul espace spécifié).
Dupliquer des caractères ne change rien au résultat et ne provoque pas d’erreur mais alourdit l’écriture inutilement.
On peut aussi définir une classe en indiquant qu’elle ne doit pas contenir un caractère ou une plage. Pour cela, placer un ‘^’ juste après le crochet d’ouverture.
Voici deux exemples :
- [^0-9] : tous les caractères sont acceptés sauf les chiffres décimaux
- [^aeiouy] : tous les caractères sont acceptés sauf les voyelles minuscules
Un match désigne une correspondance entre une regex et une partie d’un texte.
Il peut y avoir plusieurs matchs entre une regex et le texte
Exemple
Avec l’expression régulière 12, on trouve deux matchs dans la chaine 10 12 15 12 .
2.Alternatives et groupes
2.1. Choix
Le symbole | indique un choix entre deux valeurs placées à gauche et à droite du symbole.
Par exemples :
- a|b désigne un a ou un b. Ainsi les seules chaines autorisées sont a et b
- a |bonjour| BONJOUR : les chaines acceptées sont celles qui valent
un a suivi d’un espace
bonjour
Un espace suivi de BONJOUR
- chat|chien accepte les chaines chat et chien (1 match), Mon chat (1 match) chienchien (2 matchs) ou chienne (1match)
Les parenthèses spécifient un groupe. Voici un exemple illustrant la différence entre l’usage ou le non-usage des parenthèses dans une regex simple :
#abc|def accepte seulement : #abc et def. #def est refusée
#(abc|def) : accepte un # puis abc ou def. Du coup #def est cette fois-ci acceptée.
2.2. Classes et alternatives
[ab] équivaut à a|b.
Cependant [ab] sera à utiliser de préférence pour des raisons de performances.
On peut factoriser des parties de regex. Ainsi pour donner le choix entre chat et chien on peut spécifier la regex chat|chien. Mais comme ces deux possibilités commencent par les mêmes caractères ‘ch‘, on peut factoriser par ‘ch’. La regex ch(at|ien) désigne donc la même regex que chat|chien.
ch(at|ien) : apporte une très légère amélioration des performances mais elle ne se fait pas sentir sur seulement deux mots.
3.Abréviation de classes
Certaines classes peuvent être abrégées par un anti-slash suivi d’une lettre. Cette lettre en minuscule indique une acceptation de caractères tandis que qu’en majuscule elle indique qu’elle refuse des caractères.
Voici les exemples les plus utiles :
- \d (d comme digit) désigne la classe des chiffres décimaux. On peut aussi l’écrire [0-9]
- \D (no digit) accepte tous les caractères sauf les chiffres décimaux. Cette classe équivaut à [^0-9]
- \w (w comme word) accepte les chiffres, le caractère souligné, ainsi que les lettres. Selon le paramétrage du moteur PCRE2, il peut aussi accepter les lettres accentuées. \w est l’abréviation de [a-zA-Z0-9_]
- \W (no word) en est la négation et équivaut à [^a-zA-Z0-9_]
- \s désigne un espace, une tabulation (\t) ou un retour à la ligne.
Elle peut s’écrire [ \t\r\n]
- \S (négation de \s) équivaut à [^ \t\r\n]
4.Frontières
Une frontière correspond à un emplacement situé entre un caractère de mot (lettre, chiffre, ‘_’) et un caractère non-mot ou une limite de chaine (début ou fin).
Une frontière est représentée par \b (boundary).
Exemple en utilisant la chaine motmot la motarde aime ma moutarde sans dire un mot.
Dans la regex \bmot\b, mot est bordée à gauche et à droite par des non-mots.
Résultat pour la chaine étudiée : 1 match en fin de chaine : motmot la motarde aime ma moutarde sans dire un mot
La négation de \b est \B. Reprenons l’exemple précédent avec la regex \Bmot\b
mot ne doit pas cette fois-ci être bordé à gauche par un non-mot mais il doit l’être à sa droite. Autrement dit il doit être bordé à gauche par un mot) et à droite par des non-mots
Résultat : 1 match en début de chaine : motmot la motarde aime ma moutarde sans dire un mot
Le premier mot dans motmot n’est pas pris en compte car il n’est pas bordé par sa gauche par au moins un chiffre, une lettre ou un souligné.
3. Début et fin de chaine
Le symbole ^, quand il ne figure pas juste après un crochet ouvrant ( [^ ), indique que l’expression qui le suit doit se trouver au tout début de la chaine.
Par exemple ^Bonjour correspond à une chaine qui commence par Bonjour, comme : Bonjour à tous
Voici un contre-exemple : Salut, Bonjour à tous
Avec la regex ab, la chaine tabulation est trouvée par la regex
Avec la regex ^ab, la chaine tabulation n’est pas trouvée par la regex en raison de la présence du t.
Le symbole $ indique que l’expression qui le suit doit se trouver en toute fin de la chaine.
Ainsi Bonjour$ correspond à une chaine qui finit par Bonjour, telle Je vous dis Bonjour
En revanche Bonjour à tous ne respecte pas la regex.
Avec la regex ab, la chaine tabulation est trouvée par la regex
Avec la regex ab$, la chaine tabulation n’est pas trouvée par la regex
On peut spécifier ^ et $.
Avec la regex ^ab$, seule la chaine ab est trouvée par la regex
Avec la regex ^a|b$, seule les chaines a et b sont trouvées par la regex.
4.Echappement de caractères
Pour spécifier qu’on cherche le caractère ‘\’, il faut le doubler car il a une signification spéciale, \d désignant un chiffre décimal et non le caractère \ suivi du caractère d.
Avec la regex \\d, on cherche ‘\’ puis ‘d’
Le point indique un caractère quelconque. Ainsi ^a.$ trouve toute chaine de 2 caractères commençant par un ‘a’
Certains symboles ont une signification spéciale, ils seront évoqués plus loin dans cet article.
Ces caractères sont {}^$?+[]()
Pour indiquer qu’on cherche ces caractères, les faire précéder d’un ‘\’.
Exemples :
- \.\?[\^a-z] : désigne un point suivi d’un ‘?’ suivi d’un caractère parmi ‘^’ ou une lettre minuscule
\\\.\\\?\[\\\^a-z\] est la regex qui indique qu’on cherche la regex \.\?[\^a-z] elle-même dans une chaine.
5.Quantificateurs
Les quantificateurs indiquent combien de fois un caractère ou groupe de caractères doit apparaitre pour être considéré comme valide : 0 fois, 1 fois, 1 fois ou davantage, m fois au plus, au moins m fois, exactement m fois, entre m et n fois.
Voici un tableau résumant les quantificateurs disponibles et leurs usages.

6.Consommation
1. Présentation
Dans le contexte des expressions régulières, “consommer” signifie faire correspondre un ou plusieurs caractères de la chaine analysée et avancer le curseur d’analyse au-delà de ces caractères.
Une fois qu’un quantificateur a lu des caractères, ils sont considérés comme utilisés par cette partie de l’expression régulière, et le moteur passe à la suite du motif pour continuer l’analyse.
En exemple prenons la regex a+ et la chaine Chaine : aaab
Le motif a+ c’est-à-dire au moins un a, consomme aaa (il prend tous les a consécutifs).
Le curseur d’analyse est maintenant juste avant le b.
Si un autre motif suit, il commencera à tester à partir de ce b.
2. Modes de consommation
Un quantificateur peut être gourmand (greedy), non gourmand (lazy), ou possessif.
Le mode par défaut est gourmand, c’est celui qui est appliqué si on ne précise pas de mode, comme on l’a fait jusqu’à présent.
3. Mode gourmand
Le mode gourmand tente de consommer le plus de caractères possibles., tel a+ qui consomme aaa dans aaab.
Ce mode est pratique pour capturer un bloc ou une phrase.
Exemples de consommation gourmande :
1er exemple :
La regex est a.*b : un a, puis 0 ou 1 ou n caractères quelconques puis un b
La chaine à analyser est : a123b456b
Tous les caractères ont été consommés. 1 correspondance trouvée : a123b456b
2e exemple :
La regex est a.*bc : un a, puis 0 ou 1 ou n caractères quelconques puis un b puis un c
La chaine à analyser est : a123b456bce
Tous les caractères ont été consommés sauf le dernier : a123b456bce
1 correspondance trouvée : a123b456bc
3e exemple :
La regex est [0-9]{2,4} : de 2 à 4 chiffres
La chaine à analyser est a1383bc3445b
Les cinq premiers caractères sont consommés : on lit le maximum de chiffres entre 2 et 4 : on en lit 4. Le a étant lu avant, ça fait 5 caractères lus : a1383bc3445b
1 correspondance trouvée : a1383
4. Mode lazy
Pour spécifier le mode non gourmand, il faut ajouter un ? après le quantificateur.
Le but de ce mode est de consommer le moins possible.
On l’utilise par exemple quand on veut éviter de déborder lors d’un parsing HTML
Par exemple prenons la regex <tag>.*</tag>. On l’applique à la chaine <tag>premier</tag><tag>deuxième</tag>.
Le but est d’obtenir le contenu des balises <tag> mais on obtiendra toute la chaine <tag>premier</tag><tag>deuxième</tag> puisqu’on lit jusqu’au dernier </tag>.
Pour obtenir juste <tag>premier</tag>, il faut utiliser le mod lazy : <tag>*?</tag>
La chaine respectera deux fois la regex, une fois pour <tag>premier</tag> et une autre fois pour <tag>deuxième</tag>.
1er exemple :
- Regex : a.*?b : un a, puis 0 ou 1 ou n caractères quelconques puis un b
- Chaine à analyser : a123b456b
- Les 4 premiers caractères ont été consommés : on s’arrête au premier b.
- 1 correspondance trouvée : a123b
2e exemple
- Regex : a.*?bc : un a, puis 0 ou 1 ou n caractères quelconques puis un b puis un c
- Chaine à analyser : a123b456bce
- On lit jusqu’au premier b suivi d’un c
- Tous les caractères ont été consommés sauf le dernier
- 1 correspondance trouvée : a123b456bc
=> pas de différence avec le mode gourmand puisqu’il faut trouver un ‘b’ suivi d’un ‘c’, ce qui n’est pas le cas du premier b
3e exemple :
- Regex : [0-9]{2,4}? : deux 2 à 4 chiffres
- Chaine à analyser : a1383bc3445b
- Les trois premiers caractères sont consommés : on lit le minimum de chiffres entre 2 et 4 : on en lit 2.
- Le ‘a’ étant lu avant, ça fait 3 caractères lus : a1383bc3445b
- 1 correspondance trouvée : a13
5. Mode possessif
Possessif (ajout de ‘+’) : consomme tout et ne revient jamais en arrière (pas de backtracking)
Efficace en performance.
Ce mode est basé sur le mode gourmand mais les caractères lus ne sont pas pris en compte pour évaluer la regex.
Pour spécifier ce mode, ajouter un ‘+’ après le quantificateur :
*+ ++ ?+ {n, m}+
1er exemple
Regex : (.*+)A : un nombre quelconque (*) de caractères quelconques (.) puis un A
Chaine à analyser : AAAAA
Tous les caractères sont consommés : AAAAA
En effet .*+ fait consommer déjà tous les caractères. Il ne reste plus de caractères après donc pas de ‘A’ après. Du coup 0 correspondance trouvée
2e exemple
Regex : a.*+b : un a, puis 0 ou 1 ou n caractères quelconques puis un b
Chaine à analyser : a123b456b
Tous les caractères sont consommés
0 correspondance trouvée
3d exemple
Regex : [0-9]{2,4}+
Chaine à analyser : a1383bc3445b
Les 5 premiers caractères sont consommés : on lit le maximum de chiffres entre 2 et 4. On en lit donc 4.
Le a étant lu avant, ça fait 5 caractères lus : a1383bc3445b
Il reste à consommer bc3445b mais aucune consigne de la regexp ne suit celles des chiffres => la suite est acceptée
1 correspondance trouvée : a1383
7.Assertions
Dans une regex, une assertion (ou “lookaround”) est une condition qui :
- doit être vraie autour d’un motif,
- mais n’est pas incluse dans le résultat capturé.
- On cherche à trouver tel motif mais seulement s’il est placé juste avant/après tel autre.
On compte 4 types d’assertions :

Supposons qu’on recherche les virgules qui représentent les séparateurs décimaux dans une chaine de caractères.
Recherchons ces virgules dans la chaine “89,10″, “bonjour, monsieur”, “prix”: “5,10″
Sur les 5 virgules présentes, seules deux correspondent à des séparateurs décimaux.
Une virgule est un séparateur décimal quand elle est
- précédée d’au moins un chiffre => (?<=\d)
- suivie d’au moins un chiffre => (?=\d)
La regex est donc (?<=\d),(?=\d)
Résultat, 2 matchs : “89,10″, “bonjour, monsieur”, “prix”: “5,10″
Si on cherche les virgules suivies d’exactement 2 chiffres, utiliser le quantificateur {2} mais ce n’est pas suffisant.
Utilisons la regex (?<=\d),(?=\d{2}) avec la chaine “89,1”, “bonjour, monsieur”, “prix”: “5,10“, taxe:”4,125“
On obtient deux matchs : la regex voit aussi 4,125 alors que la virgule est suivie par plus de 2 chiffres, comme si on avait spécifié {2,} au lieu de {2}
=> Les lookaheads peuvent laisser passer plus que ce qu’on attend s’ils ne sont pas bien encadrés. Il faut donc indiquer qu’après les deux chiffres il ne doit pas y en avoir d’autres : (?=\d{2}(?!\d)).
8.Groupe
1.Groupe capturant
Un groupe est ce qui est placé entre des parenthèses. Par défaut il est capturant : il sert alors à capturer un morceau de texte. Ce texte pourra être utilisé après les matchs par un langage de programmation en vue par exemple d’un remplacement.
Tout groupe capturant spécifié porte un numéro attribué automatiquement : 1, 2, 3, …
Voici un exemple d’utilisation :
On dispose de la chaine Email : pierre@example.com. On souhaite récupérer le mail.
Le mail est ce qui suit Email suivi d’espaces éventuels puis d’un ‘:’ puis d’espaces éventuels.
La regex est donc ‘Email\s*:\s*(\S+)’
(\S+) est un groupe capturant. Son numéro est 1, c’est le seul groupe de la regex.
On pourra récupérer le contenu capturé par le groupe dans un langage de programmation.
Voici un exemple en Python :

2.Groupe nommé
Un groupe nommé est un groupe capturant qui utilise un nom pour le groupe au lieu d’un numéro. C’est le créateur de la regex qui choisit le nom.
Il est reconnu par PCRE mais pas forcément par d’autres dialectes.
Un groupe nommé est un groupe, il se place entre parenthèses et commence par ?P, suivi du nom du groupe entre < > puis suivi de l’expression regex elle-même.
Voici un exemple : (?P<nomGroupe>\w+[0-9]{5})
On peut accéder au groupe via le nom dans un langage de programmation
Voici le même exemple que précédemment en utilisant cette fois-ci un groupe nommé :

3.Groupe non capturant
Un groupe non capturant regroupe mais ne capture pas le contenu. Un tel groupe commence par ?:
Exemple : (?:\d{3}-){2}\d{4}
La regex reconnaît une séquence comme 123-456-7890 mais ne crée pas de groupe accessible (group(1) etc.).
Quand on n’a pas besoin de capturer, mieux vaut utiliser un groupe non capturant car il consomme moins de mémoire.
9.Principaux cas d’usages des regex
On peut être amené à définir des regex pour :
-
Contrôler la valeur d’une chaine (zone de saisie, paramètre, …)
-
Analyser des fichiers texte structurés (csv, log, …)
-
Remplacer des chaines par d’autres dans des textes
-
Rechercher des informations dans un texte
-
Nettoyer des données.
1. Contrôle de la valeur d’une chaine
On souhaite par exemple vérifier que le contenu d’une chaine correspond bien à un numéro de téléphone, à un mail, à un numéro de sécurité social, à un IBAN, à un commentaire dans du code technique…
Deux cas de figures à considérer :
- Côté client : validation d’un champ de saisie
- Côté serveur : validation des paramètres d’une fonction / méthode
Dans le premier cas, le but est d’empêcher un aller-retour client-serveur qui n’aboutirait pas car le serveur refuserait la valeur du champ.
L’utilisation de regex (notamment en JavaScript ou NCL) permet une optimisation de l’application (gain de temps réseau) et évite de charger le serveur pour rien.
Dans le second cas, le but est de sécuriser le serveur afin
- qu’il ne plante pas si des paramètres ne sont pas conformes
- qu’il bloque un traitement malveillant (injection SQL par exemple)
Important : le serveur ne doit jamais faire confiance aux clients, il doit être sécurisé, que les clients le soient aussi ou non.
Il est recommandé de créer des contraintes check dans les tables de bases de données relationnelles, ce qui empêchera l’insertion ou la modification de données ne respectant pas la regex. Ainsi même si au moins un serveur d’application n’effectue pas son travail de vérification, la base de données bloquera l’action. La base n’a pas non plus à faire confiance au serveur d’applications.
Exemple de création d’une table postgreSQL utilisant une regex :
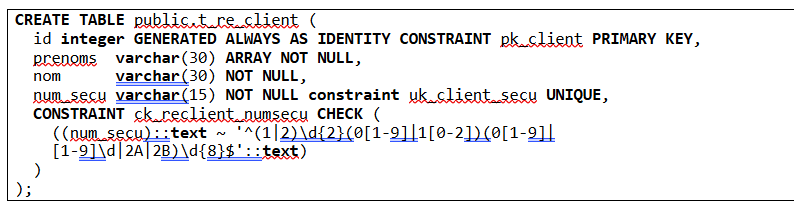
Remarque : avant 1976, le code insee des communes corses présent dans le numéro de sécurité social commençait par ‘20’ et non par ‘2A’ ou ‘2B’. De même jusqu’en 1975 le ‘96’ était accepté pour les personnes nées à l’étranger. Il peut être judicieux de ne pas interdire ces deux valeurs si on veut gérer des personnes de n’importe quel âge ou décédées.
2.Analyse de fichiers structurés
Supposons qu’on a à notre disposition des logs apache :
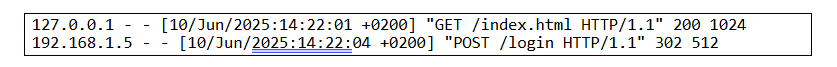
On peut utiliser des regex pour extraire de chaque ligne :
- l’adresse IP
- la date
- la méthode http
- la ressource demandée
- le code de réponse
- la taille de la réponse.
Exemple d’une telle regex qui utilise des groupes nommés :
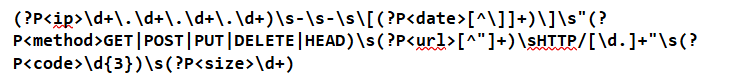
3.Remplacer des chaines par d'autres dans des textes
Placeholders
Dans du code technique on peut utiliser une regex pour remplacer des chaines par une autre dans un texte.
Voici un exemple avec le texte suivant :
Bonjour [sexe] [prenom][nom]
Sauf erreur de notre part vous n’avez pas réglé la facture [numero_facture].
Afin d’éviter toute interruption de service, nous vous demandons de la régler dans les plus brefs délais.
Recevez [sexe] [nom] nos cordiales salutations
[sexe] est à remplacer par Mme. [prenom] est à remplacer par Ella [nom] est à remplacer par Papayé [numero_facture] est à remplacer par A1245F
L’expression régulière \[([a-z_]+)\] permet de capturer les mots entre crochets. Au moyen d’un langage de programmation on effectuera la substitution.
Voici un exemple en python :

4. Changement de format
Voici un deuxième exemple. Le but est de transformer un flux JSON5 en flux JSON.
C’est ce que fait Oracle 23ai quand on lui demande d’insérer une donnée JSON5 : il l’accepte mais la stocke en JSON
Pour passer au format JSON il faudra
- Supprimer les commentaires (// ou /* … */)
- Placer les clés entre double-quotes si ce n’est pas déjà le cas
- Transformer les quotes simples en double-quotes
- Supprimer les virgules finales dans les tableaux ou objets
- Remplacer Infinity et Nan par un valeur connue de JSON, par exemple null
Voici le code python proposé :
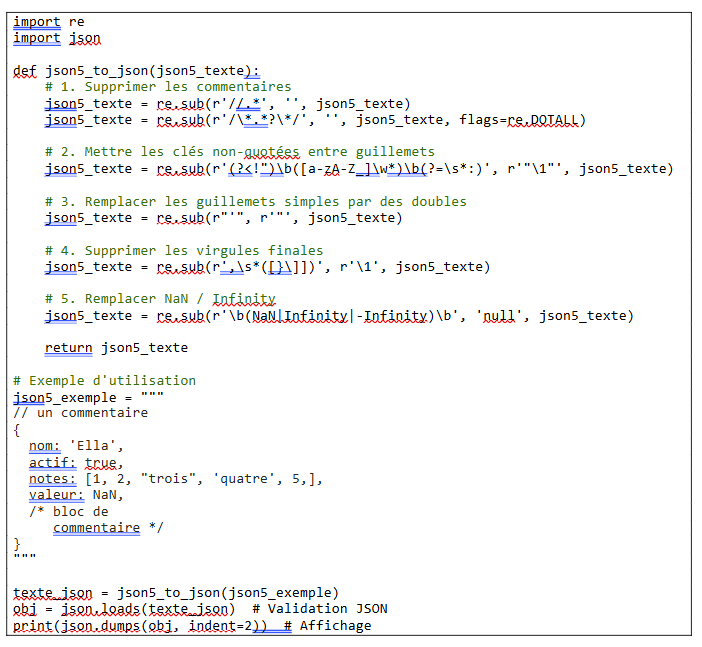
Ce qui donne :

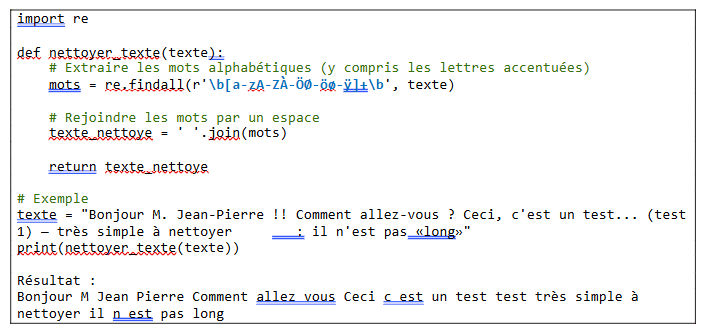
5.Nettoyer des données
Un regex peut supprimer des caractères invalides ou de présentation. Ainsi si un utilisateur saisit un numéro de téléphone avec des espaces, ces derniers pourront être supprimés par une regex.
Pour rendre un texte lisible, on peut utiliser une regex pour supprimer les caractères non ascii ou non imprimables.
On peut aussi supprimer d’un texte tous les caractères de ponctuation afin de ne garder que les mots dans le but de les analyser par la suite.
Voici le code python :

Auteur
